こんにちは。アウモ株式会社でインターンをしておりますイワミ(@B_Sardine)と申します。東京都立大学のM2 で、UAVの航空交通管理に関する研究をしています。aumo では主に記事メディアを中心とした開発をしています。
今回から何回かに分けて、6月頃から徐々に行われているGoogle Core Updateにて検索結果に影響を与えると言われているUX指標「Core Web Vitals」についての対策を書き連ねようと思います。 前回の記事では、主にLCPに焦点を当てたバックエンド側の改善施策でしたが、今回は第一弾として「パフォーマンスの計測基盤の自作」について述べていこうと思います。
分析基盤の構築
Core Web Vitals を始めとした、webパフォーマンスを測るパラメータは多く存在します。Core Web Vitals はその中でも特にGoogle が重要視しているパラメータです。
計測ツール
これらを改善していくのですが、まずは現状のスコアおよびパラメータがどれくらいなのかということを把握しなければなりません。
「Measure,Don’t Guess」という言葉は有名ですね。 (余談ですが、この言葉は誰が言い出したかどうかは色々な説があるらしく、ベル研でUNIXの開発に携わっていたRobert C. Pikeという説などがあるらしいです)
一般的にWEBのパフォーマンスを計測するツールとしては以下のようなものが一例としてあります。
| ツール名 | 合成モニタリング | リアルユーザーモニタリング |
|---|---|---|
| Google Search Console | × | ○ |
| Lighthouse | ○ | × |
| PageSpeed Insights | ○ | ○ |
| SpeedCurve | ○ | ○ |
| Google CrUX | × | ○ |
| New Relic | ○ | ○ |
ここで、合成モニタリングとリアルユーザーモニタリングの違いを説明します。
合成モニタリングとリアルユーザーモニタリング
速度改善のためのバイブルとして有名な「超速! Webページ速度改善ガイド」によると…
合成モニタリング──定常的な計測と詳細なレポート
合成モニタリングは、計測用の仮想環境などから、同じ条件で定期的に繰り返し計測を行ってモニタリングします。特定の環境から繰り返し計測するので、計測ごとの揺らぎが抑えられます。また、計測時の詳細なレポートを取得できるので、具体的な改善にも役立ちます。
佐藤 歩,泉水 翔吾. 超速! Webページ速度改善ガイド ── 使いやすさは「速さ」から始まる (WEB+DB PRESS plus) (Japanese Edition) (Kindle の位置No.1578-1581). Kindle 版.
リアルユーザーモニタリング──ユーザーが体験した実測データの収集
リアルユーザーモニタリングでは、実際のエンドユーザーがWebページを開いたときに都度、Webページに仕込んだ専用スクリプトによって実測データをサーバに投げて収集します。エンドユーザーが実際に利用したときの値やその分布を収集できますが、エンドユーザーの手もとで実行されたときの詳細なレポートはわからないので、合成モニタリングと比べて、改善の具体的な手がかりにはなりません。
佐藤 歩,泉水 翔吾. 超速! Webページ速度改善ガイド ── 使いやすさは「速さ」から始まる (WEB+DB PRESS plus) (Japanese Edition) (Kindle の位置No.1593-1598). Kindle 版.
みなさんが PageSpeed Insights などを利用した際、「ラボデータ・フィールドデータ」などというワードを見ると思いますが、これらは以下のように対応しています。
- ラボデータ = 合成モニタリング
- フィールドデータ = リアルユーザーモニタリング
超速本の通りですが、合成モニタリングは同じ仮想環境から速度チェックをその場で行えるので、どこがボトルネックになっているかなどを確認して対策することができます。一方、リアルユーザーモニタリングは読んで字のごとく、実際にユーザーがそのサイトを訪れた際のパフォーマンスを計測しているものです。合成モニタリングがその場で計測してすぐに結果を見ることができるのに対し、一般的にリアルユーザーモニタリングは長期間計測するため、施策の効果などを見るにはあまり向いていません。(例として、CrUXは毎月第二火曜日に更新されます)
ツールを使用する際は、この二つの違いを理解した上で使用する必要があります。そして後述しますが、この違いがCLSには大きく出てくるので注意が必要です。
合成モニタリングの結果を継続的に見たい
PageSpeed Insights は非常に便利なツールであり、URLを入力するだけで即座にラボデータの計測を行ってくれます。ですが、これを毎日(また任意のタイミングで)連続的に計測し、結果の変化を見たいというニーズが出てきます。
このモニタリング機能は、SpeedCurve などの有料ツールには備わっていますが、今回は簡易的に PageSpeed Insights API を利用して自作しました。
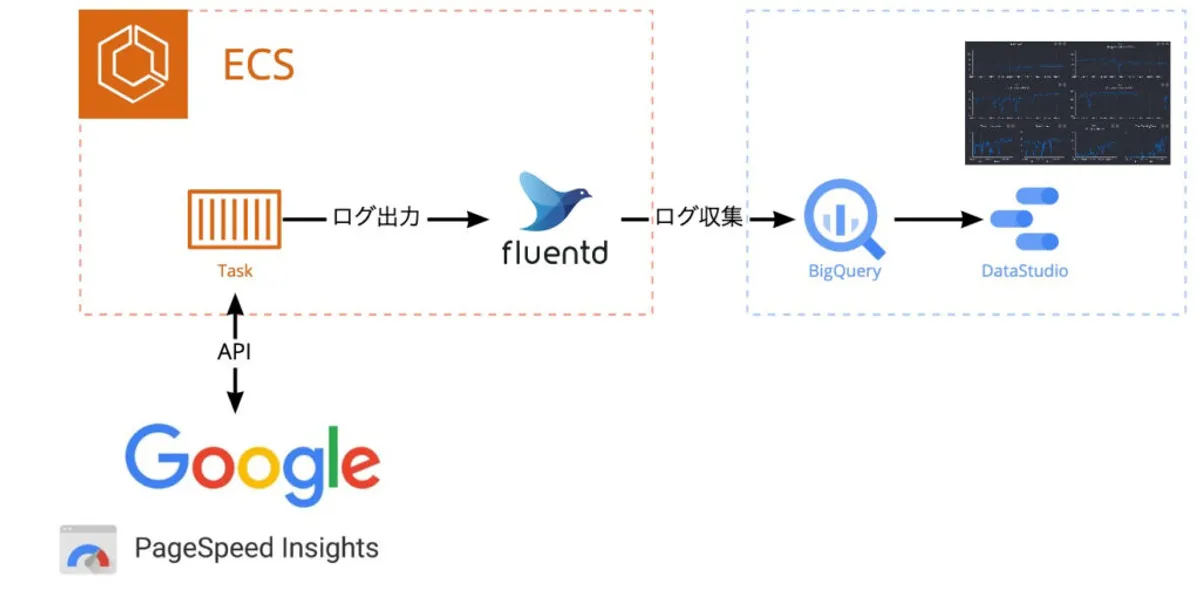
構成
先ほどの PageSpeed Insights には API が存在します。これを利用するとブラウザで表示されている全てのデータに加えて、表示しきれていないデータも取得することができます。
これを利用して計測ツールを作成していきます。使うツールは以下です。
- PageSpeed Insights API
- AWS ECS タスク
- BigQuery
- Fluentd
- Data Studio
流れとしては、以下です。
- Rails の Rake タスクでAPI を叩き、結果を Fluentd が拾える形で出力する
- Fluentd はデータを BigQuery に流す
- Data Studio で可視化する
まず、APIからデータを取得します。
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={target_page}
最低限必要なのは、計測対象のページURLです。その他にも色々とオプションがあります。
クエリの中にAPI キーを入れることができますが、これは一定期間のリクエスト数がある数を超える場合には必要になります。今回の場合は連続してそこそこの回数APIを叩くので追加しました。というわけで、結果的に以下のようなGET リクエストを叩きました。
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=#{target_page}?key=#{ENV["PAGE_SPEED_INSIGHT_API_KEY"]}?strategy=#{strategy}?locale=#{locale}
strategy は対象とする端末(mobile, desktopなど)です。
計測対象とするページは配列で持っておき、片っ端からこの配列に格納されていページURLを叩くという手法をとっています。ちなみにこの配列は Rails の管理画面で変更できるため、新しく追加したいページや合わせて比較したい他社のページなど、自由に追加することができます。
返ってくるJSONは、次のような形です。
{
"captchaResult": string,
"kind": "pagespeedonline#result",
"id": string,
"loadingExperience": {
"id": string,
"metrics": {
(key): {
"percentile": integer,
"distributions": [
{
"min": integer,
"max": integer,
"proportion": double
}
],
"category": string
}
},
"overall_category": string,
"initial_url": string
},
"originLoadingExperience": {
"id": string,
"metrics": {
(key): {
"percentile": integer,
"distributions": [
{
"min": integer,
"max": integer,
"proportion": double
}
],
"category": string
}
},
"overall_category": string,
"initial_url": string
},
"lighthouseResult": {
"requestedUrl": string,
"finalUrl": string,
"lighthouseVersion": string,
"userAgent": string,
"fetchTime": string,
"environment": {
"networkUserAgent": string,
"hostUserAgent": string,
"benchmarkIndex": double
},
"runWarnings": [
(value)
],
"configSettings": {
"emulatedFormFactor": string,
"locale": string,
"onlyCategories": (value),
"onlyCategories": (value)
},
"audits": {
(key): {
"id": string,
"title": string,
"description": string,
"score": (value),
"score": (value),
"scoreDisplayMode": string,
"displayValue": string,
"explanation": string,
"errorMessage": string,
"warnings": (value),
"warnings": (value),
"details": {
(key): (value)
}
}
},
"categories": {
(key): {
"id": string,
"title": string,
"description": string,
"score": (value),
"score": (value),
"manualDescription": string,
"auditRefs": [
{
"id": string,
"weight": double,
"group": string
}
]
}
},
"categoryGroups": {
(key): {
"title": string,
"description": string
}
},
"runtimeError": {
"code": string,
"message": string
},
"timing": {
"total": double
},
"i18n": {
"rendererFormattedStrings": {
"varianceDisclaimer": string,
"opportunityResourceColumnLabel": string,
"opportunitySavingsColumnLabel": string,
"errorMissingAuditInfo": string,
"errorLabel": string,
"warningHeader": string,
"auditGroupExpandTooltip": string,
"passedAuditsGroupTitle": string,
"notApplicableAuditsGroupTitle": string,
"manualAuditsGroupTitle": string,
"toplevelWarningsMessage": string,
"scorescaleLabel": string,
"crcLongestDurationLabel": string,
"crcInitialNavigation": string,
"lsPerformanceCategoryDescription": string,
"labDataTitle": string
}
}
},
"analysisUTCTimestamp": string,
"version": {
"major": integer,
"minor": integer
}
} 実際のデータはこれよりもはるかに多いです(おそらくクエリで間引けます)。この中で今回使用したのは、lighthouseResult.audits.{欲しいパラメータ} です。
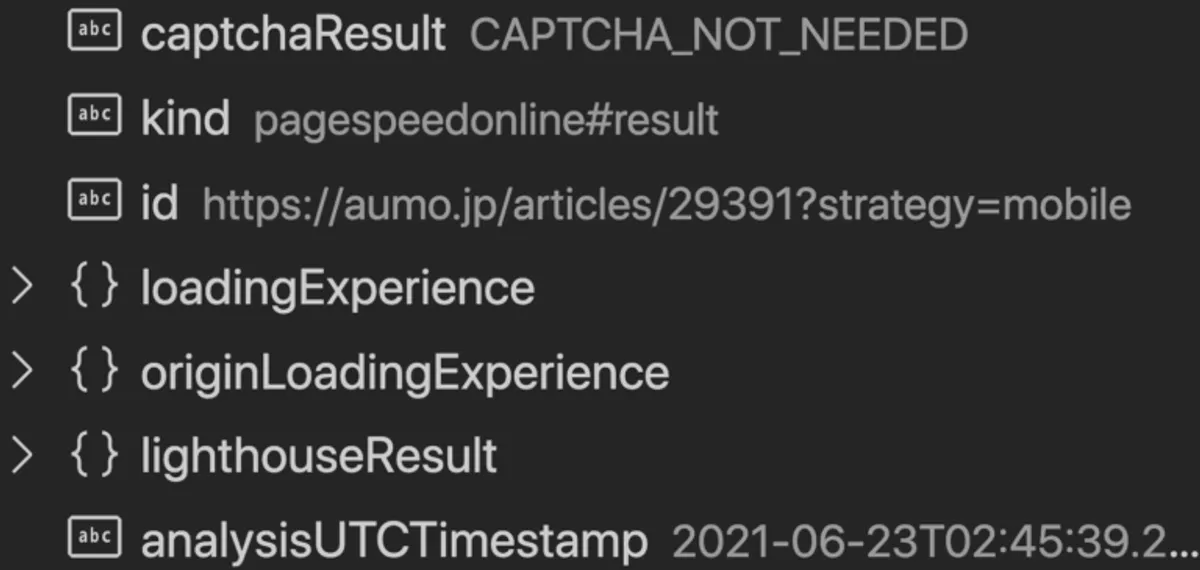
パラメータ名からも分かるかと思いますが、内部的には Lighthouse を利用して計測しているようです。 分析の環境としては、モバイル端末とバソコンの両方をエミュレートする Blink レンダリングエンジンを使用しているようです。
Lighthouse CLI は存在しますが、これはおそらくそのコマンドを実行している端末のスペックや状況に依存するので、 CIなどで分離する以外はこのAPIの方が実行環境を向こうに任せられるので、ある程度一定のデータが手に入ると思います。
さて、あとは欲しいデータを Fluentd でBigQueryに流し、Data Studio で可視化します。するとこのようになります。
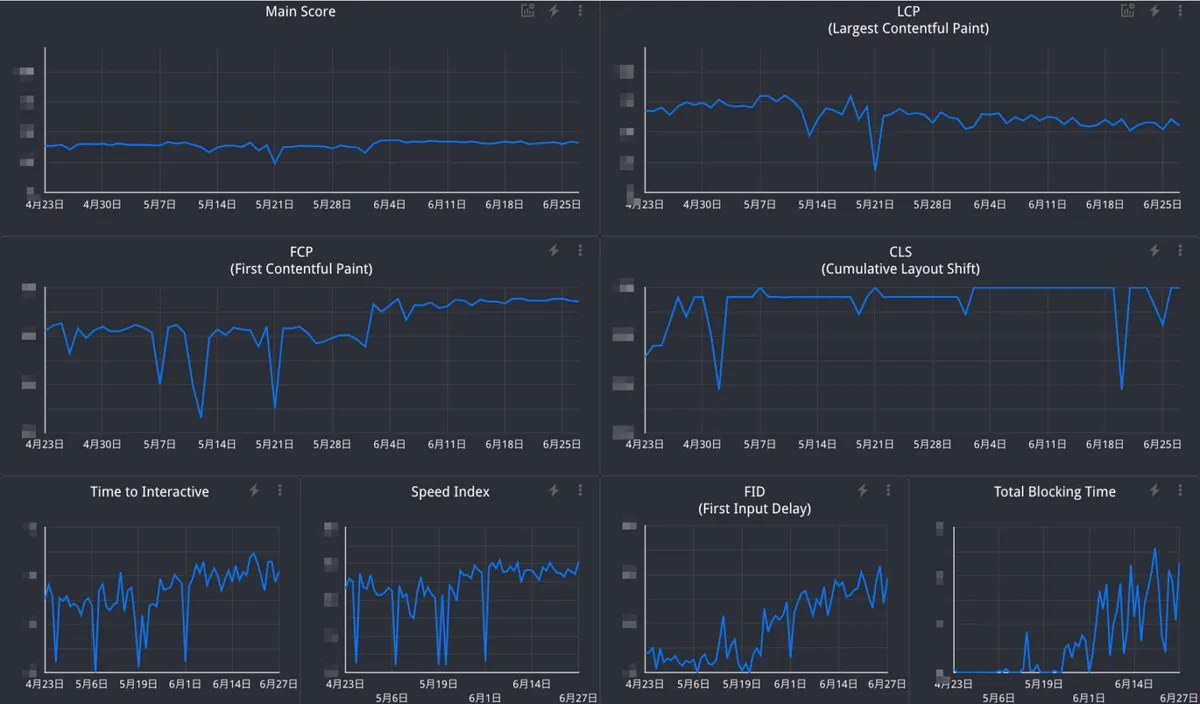
たまに計測が途中で止まってしまい、正しく計測できてない日がありますが、概ね傾向を把握できています。
今回は毎日回しているバッチで計測しましたが、CIに組み込んでデプロイごとに計測して前後の変化を見るなども出来ると思います。
※ CIに組み込む際は、Lighouse の CLI を CI 用に使えるようにしているリポジトリがあったので、こちらを使用したほうがいいかもしれません。
まとめ
今回は PageSpeed Insights API を使用して、パフォーマンスの計測基盤を作成しました。 Core Update に向けた対策を進める中でも、やはり日々定点観測することは非常に重要であると感じました。
SpeedCurve などは各パラメータの悪化を検知して通知してくれる機能があるそうですが、今回の場合でも計測時のパラメータをチェックし、 閾値以下の場合は Webhook による Slack 通知送るなどの実装で実現できそうです。 (DataStudio のグラフ画像を Slack へ送信するには、権限周りで少々ややこしい実装をする必要がありますが…)
次回は、今回少し触れていたCLS について少々深堀していきたいと思います。ここでは合成モニタリングとリアルユーザーモニタリングを理解しながら進めていく必要があります。
それでは、次回をお楽しみに。